采用可配置处理器技术构建多发射向量DSP
音频、视频、图像等所有媒体的数字化对信号处理提出了越来越高的要求,这些数字信号数据内容需要建立、存储、传输和重放。同时,越来越多的通信和娱乐传输系统是便携式的,极大地提高了信号处理的带宽。日益增长的信号处理负载使得电气功耗成为信号处理系统的制约因素。
DSP是进行数字信号处理的绝好选择,因为数字信号处理器可以编程,并且在当今数字媒体处理飞速变化的世界里可以容易地处理众多变化的标准。然而,由于其通用性使得通用DSP并非对所有应用都是功耗有效的。
硬线连接的信号处理模块通常是比较功耗有效的,但是缺少DSP那样的灵活性和可编程特性。可配置处理器技术在DSP的固定ISA(指令集体系结构)灵活性和可编程特性与硬线连接模块的功耗有效性之间建立起桥梁,使得从各种特性和可编程DSP中建立起针对某一特定任务的正确属性。Tensilica的Vectra LX解释了这种概念。Vectra LX是一个定点的向量DSP引擎,该引擎是通过配置选项在Xtensa LX可配置处理器的基础上建立起来的。
Vectra LX定点DSP引擎是Xtensa LX微处理器内核的一种配置。该定点DSP引擎是一个3发射的SIMD处理器,具有四个乘法器/累加器(四个MAC),它可以处理128位的向量。128位向量可以分成8个16位或者4个32位的元素。整个Vectra LX DSP引擎是用TIE(Tensilica’s Instruction Extension)语言开发的,通过修改可以适合目标应用领域。正像在图1所示的那样,Vectra LX DSP引擎增加了16个向量寄存器(每个寄存器160位宽)、四个128位的向量队列寄存器、第二个加载/存储单元和210多条现有Xtensa LX处理器指令集体系结构中的通用DSP指令。

图1:Vectra LX DSP引擎配置选项增加了16个向量寄存器(每个宽度160位),四个128位的向量对齐寄存器,第二个load/store单元以及为Xtensa LX 现有的ISA(指令集体系结构)增添的210多条通用DSP指令。
基本的Xtensa LX处理器是一个单发射的微处理器,具有16位和24位指令。但是,Tensilica的处理器产生器能够让开发人员增加更宽的指令字长。通过一种称为可变长度指令扩展FLIX(Flexible-Length Instruction Extensions)的技术为处理器指令集增添多个独立操作。FLIX指令宽度可以为32位或者64位,并且由于Xtensa LX处理器已经设计成可以处理多种指令宽度,因此多操作FLIX指令可以在处理器代码流中自由组合,并且可以和现有的单发射Xtensa LX处理器指令连接在一起。
当开发人员选择Vectra LX DSP引擎配置选项时,Tensilica的处理器产生器会自动将DSP引擎的RTL代码添加到可综合的 Xtensa LX处理器中。新的Vectra LX指令被添加到处理器自动产生的软件工具集(编译器、汇编器、调试器、指令集仿真器ISS和实时操作系统RTOS接口)中。Vectra LX使得Xtensa LX处理器门数增加20万到25万门。这些增加的门数中的大部分用于构建Vectra LX DSP引擎中的寄存器和执行部件,因为通用处理器和DSP引擎扩展可以共享处理器中现有的取指令和指令译码部件,所以那些硬件模块不需要重新复制。然而,需要增加一些逻辑用于对新的指令进行译码。图2表示Vectra LX DSP引擎配置选项中增加的寄存器和执行部件框图。
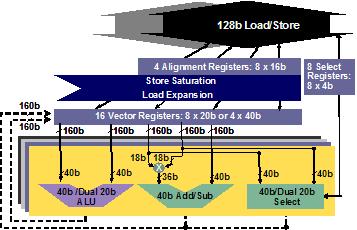
图2:Vectra LX DSP引擎的160位向量寄存器与四个相同的SIMD部件相连,每个部件包括一个向量ALU、一个独立的加法/减法部件、一个乘法器和一个选择部件。对齐寄存器支持非对齐加载和存储操作,并作为中间结果寄存器。此类操作用于将160位向量寄存器转换成128位向量数据的加载扩展操作和将128位向量数据转换成160位向量寄存器的存储饱和操作。
图3表示3操作Vectra LX指令字格式。指令字中最右边四位表示该指令宽度为64位。剩下的60位指令字长度不等地分布在三个操作指令槽中:一个24位和两个18位的指令槽。Vectra LX指令字中的24位操作指令槽(指令字中第4位到第27位)可放置Xtensa LX处理器中所有80条基本指令,包括控制第一个加载/存储单元的操作。该操作指令槽还可以处理扩展的128位加载/存储指令,此指令可将信息存到Vectra LX宽向量寄存器中,也可以从该向量寄存器读出信息。
![]()
图3:64位的Vectra LX指令字长度不等地分布在三个操作指令槽中:一个24位的指令槽和两个18位的指令槽。指令字中最右边四位是固定的,表示该指令宽度为64位。
24位的操作指令槽能提供足够宽的编码位数,允许加载和存储指令在指令槽中指定对齐或者非对齐加载和存储操作,如图4所示。非对齐加载和存储操作帮助相关的向量化编译器处理存储器数据阵列,这些数据阵列可以任意方式对齐,因为编译器产生的代码有时是非对齐的数据阵列,这将降低DSP的性能。然而,这种性能损失可以通过DSP引擎以非对齐加载和存储操作方式提供的支持加以补偿。

图4:Vectra LX的加载和存储操作单元由处理器指令字中的24位指令槽进行控制,通过采用128位对齐寄存器保存部分向量来完成对齐和非对齐加载和存储操作。在由第一个部分向量填满对齐寄存器后,处理器可以每个时钟周期完成一个未对齐的加载或者存储操作。
Vectra LX DSP引擎的对齐寄存器提供部分向量存储功能,这些对齐寄存器在非对齐加载或者存储字符串的开始用第一个部分向量进行初始化。后续的非对齐加载或者存储操作隐含地和新的向量数据进行合并,这些向量数据经过循环移位并和部分对齐寄存器内容相连接,在对齐寄存器中将整个向量组合在一起。这些非对齐加载和存储操作还为下一个非对齐加载或者存储操作准备好对齐寄存器,以便使得一系列连续的非对齐加载或者存储操作能和对齐数据近似相同的效率将数据送入或者送出非对齐数据阵列。
Vectra LX DSP引擎采用第一个18位操作指令槽(第28位到第45位)来放置4x40-bit 的SIMD单指令流多数据流乘累加MAC 操作。该指令槽还执行DSP引擎的选择操作,该操作可以将两个源向量寄存器中的八个16位寄存器组合在一起,如图5所示。
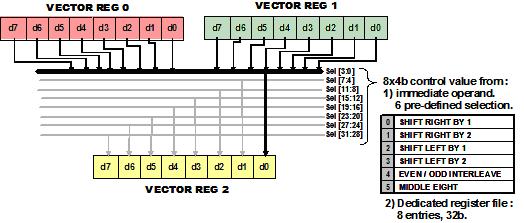
图5:Vectra LX DSP引擎的一系列选择操作将两个源向量寄存器中的八个16位寄存器组合在一起,形成一个寄存器。选择操作用于实现向量操作。
Vectra LX处理器选择操作可以用于实现诸如复制、循环移位、移位和数据交织等向量操作。第二个18位操作指令槽(第46位到第63位)保存DSP引擎的4x40位和 8x20位的SIMD单指令流多数据流ALU操作以及那些用于控制处理器中第二个加载/存储单元的操作,该加载/存储单元能执行数据对齐操作、128位向量的加载和存储操作。
Xtensa LX和Vectra LX处理器通过三个操作指令槽有效地执行DSP代码,图6表示一个256点的基4复数FFT算法中的一个紧凑循环程序。四个乘累加MAC单元全部得到了利用(如图6中的中间一列),并且另外两个指令槽也得到了充分利用。这样组织程序的结果导致Vectra LX DSP引擎极大地减少了用Xtensa LX处理器来执行DSP任务所需要的时钟周期数。图7列出了256点的基4 FFT算法的时钟周期数。
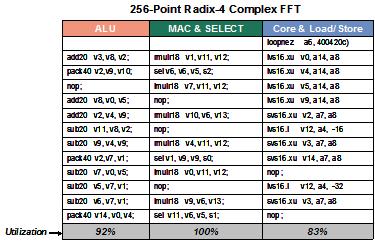
图6:一个256点的基4复数FFT算法全部利用了Vectra LX DSP引擎中的四个乘累加MAC单元(如图6中的中间一列),并且另外两个指令槽也得到了充分利用。

图7:为Vectra LX DSP引擎增加SIMD和多操作功能,执行一个256点的基4复数FFT算法使得时钟周期数降到944个,性能大约提高156倍。
一个最基本的Xtensa LX处理器配置在计算一个256点的基4复数FFT算法时需要155000个时钟周期。如果为基本处理器配置增加一个32位乘法器,那么执行相同的FFT算法需要23633个时钟周期,减少接近一个数量级;如果像在Vectra LX DSP引擎中那样增加SIMD和多操作能力,则需要944个时钟周期,减少两个以上的数量级,性能大约提高156倍。
开发DSP体系结构性能要求有相关的软件工具,需要理解和有效地运用DSP的结构特征。一个称为XCC的向量化C/C++编译器支持Xtensa LX和Vectra LX体系结构。该编译器能够按照和传统C数据类型相同的方式来自动处理向量数据类型,如图8所示。向量类型的转换是隐含进行的。

图8:XCC编译器按照和传统C数据类型相同的方式自动处理向量数据类型。向量数据类型的转换是隐含进行的。
为了获得更高的处理器性能,XCC编译器利用Vectra LX单指令流多数据流执行部件寻求各种机会对代码进行向量化,主要针对循环语句,如图9所示。在对DSP代码进行编译时,XCC编译器产生一串连续的Vectra LX操作,然后调度这些操作,并将其封装成Vectra LX宽指令字,如图10所示。调度汇编器对汇编代码也做相同的操作。

图9:为了获得更高的处理器性能,XCC编译器利用Vectra LX单指令流多数据流执行部件寻求各种机会对代码进行向量化,主要针对循环语句。
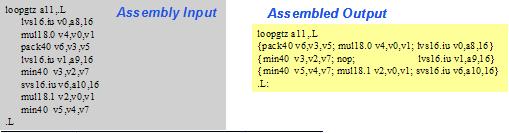
图10: XCC编译器产生一串连续的Vectra LX操作,但由调度汇编器将这些操作捆绑到Vectra LX宽指令字中。
应用程序的性能证明了针对处理器或者DSP采用新的体系结构是值得的。你可以从BDTIsimMark2000™典型程序分数值看到通过FLIX语言使得Xtensa LX处理器计算性能得到提高的情况。BDTIsimMark2000是从BDTI典型程序中提取出来的,用于全面衡量DSP速度的提升情况。BDTI典型程序是由伯克利设计技术公司开发并经过独立验证的一组DSP测试程序,由于它基于真实的DSP算法内核基准程序,所以BDTIsimMark2000能够比MIPS或者MFLOPS那些传统的简单测量方法更准确地反映出处理器的信号处理能力。
图11给出了Xtensa LX和Vectra LX 处理器的BDTIsimMark2000分值,并和另外CEVA-X1620和 StarCore SC1400两款非常快的DSP核进行了分值比较。BDTIsimMark2000分值基于仿真结果。测试时,Xtensa LX和Vectra LX处理器仿真的时钟速度是370 MHz,该处理器可以采用130纳米IC工艺实现,采用标准的综合和布局布线工具。

图11:Xtensa LX和Vectra LX处理器增加11条DSP指令获得BDTI公司DSP核的最快BDTIsimMark2000分值
BDTIsimMark2000™提供DSP的综合评测。Xtensa LX的分值是假设为处理器增加11条定制TIE指令,内核面积扩大16%。许可证费用可以高于或者低于定制的水平。其它DSP核的分值评测是假设没有协处理器或者其它定制模块。更多的信息参见www.BDTI.com。
注意到,Xtensa LX和Vectra LX处理器的典型程序分值不是单纯通过为Xtensa LX 增加Vectra LX DSP引擎得到的。利用TIE语言增加了11条用户定制扩展指令,并通过BDTI进一步提高了处理器在执行典型程序时的性能。由于Xtensa LX是可配置的,因此通过BDTI典型程序的扩展可以直接反映出可配置Xtensa LX处理器在实际应用中的使用情况。
事实上,整个Vectra LX DSP引擎是通过TIE语言开发的(参见图12),SOC开发人员可以对其进行修改以便适合目标应用。采用可配置处理器的一个重要理由就是可以最大限度地将处理器的能力应用于目标应用。在这种情况下,BDTI典型程序就是目标应用,但是目标应用也可以是音频、视频、图像或者其它类型的信号处理。
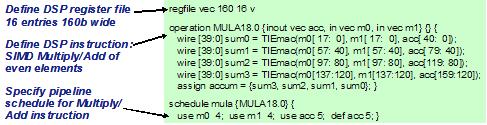
图12:整个Vectra LX DSP引擎是通过TIE语言开发的(Tensilica’s Instruction Extension),经过修改可以适合目标应用。在此,三行TIE语句定义了DSP引擎的SIMD乘法指令