多核与多绪在各种运算体系的整合与对抗
导言:多核心架构是处理器的主流设计方式之一,不论在超级电脑、伺服器领域、个人电脑,小至掌上型移动装置,不论是同质核心,甚或是异质核心,多核架构带给消费者的好处也越来越明显,但是多核架构必须结合多个核心,在电路规模以及晶片复杂度上的增加必须藉由制程来抵消,而多执行绪虽然也可以跟多核架构兼容并蓄,但在嵌入式环境中,却是呈现分庭抗礼的状态,两者各有优势,但也有其缺点,短期之内可预见此2大架构在嵌入式应用中各擅胜场。
多核与多执行绪架构其实都是相当成熟且具有历史的技术,两者其实可以相辅相成,在大型电脑、工作站等领域,其采用的处理器核心往往都同时具备此2大技术,而且在效能表现上取得了相当优秀的结果,然而在嵌入式应用中,却因为2大嵌入式处理器厂商的开发走向差异,让多核心与多执行绪技术成为各家独到的特性,并以此为卖点,然而随着处理器架构的进步,以及半导体制程的进化,两者其实也有可能结合,毕竟这2种技术其实没有太多相抵之处,目前无法在嵌入式处理器中併行,只能看成是厂商的技术限制,也或者是市场行销取向的不同,如果哪天某阵营突然推出结合两者优点的处理器,其实也在预料之中。
图说:IBM的多核技术在高阶运算中相当普及。
多核心的架构特色
处理器的多核心技术其实已经行之有年,对于特定应用,多核心架构的确能够对效能起非常大的正面帮助,但是一般人在多核心对系统效能的帮助其实会有点误会,对基于多核心架构处理器的系统来说,多核心处理器并不能把单一执行绪的工作平均切割分配给处理器中的不同核心。
举个比较浅显的例子:单核心处理器在进行单一工作处理时,就好像1个工人在扫地,而场景转换到多核心处理器时,那扫地的工作并不会平均分配给多个工人,而仍然是1位工人在扫地,其他工人只能在旁边看,系统只能指定其他工人去进行别的工作,比如说浇花、洗衣或者是剪树,扫地这件工作本身在同1个时间点内依然只能由同1个工人进行。而多核心架构必须整合颗或多颗核心,在处理单元上多少都会有重复,若工作排程分配机制设计不佳、作业系统配合度不够高,最佳化程度不够,或者是工作本身过于单纯,那等于是会有大批的电晶体处于闲置状态,形成浪费。
多执行绪的技术特性
至于在多执行绪方面,我们可以将之想像成具有1个复杂的大脑,而且有8只手脚的工人,这种架构在应用上,可以视工作的需求,来分配其大脑和手脚的工作负载,当大脑觉得正在进行的工作内容单纯又轻松,那么可以依照其预设的工作模式,来将大脑的思考能力和手脚进行切割,将其分散出去进行其他工作,如果当目前的执行绪本身复杂度高,或者是仅处理单一执行绪,则可以将所有执行单元(大脑和手脚)结合为一体,全力应付目前的工作。
乍看之下,多执行绪在应用的弹性方面要高出许多,但是多执行序架构的处理器在本质上仍为单一处理器(以前例而言,则是基于同1个大脑),即使能够同时处理多个执行绪,但是执行单元总数仍有其限制,在资源有限(快取记忆体、分支预测单元、整数、浮点运算单元等等)的状况之下,要如何为特定应用最佳化可能是相当困难的1件事。
多核心/多执行绪在PC平台上的发展
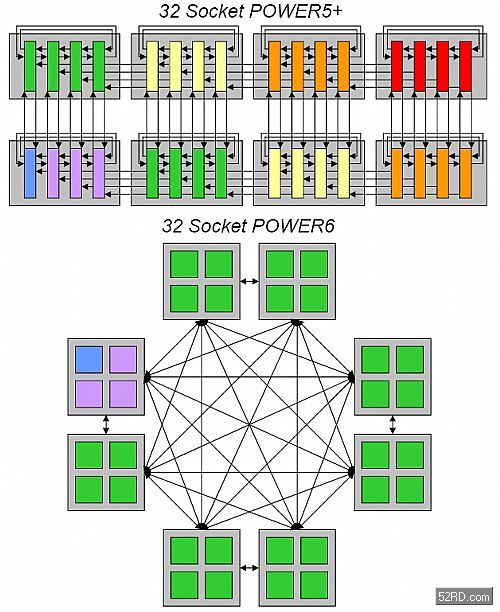
我们以x86处理器为例,其实多执行绪的引进要早于多核心体系,这主要是肇因于半导体制程的限制,在过去的制程技术之下,要导入多核心架构是相当困难的1件事,除了核心热功耗问题难以解决以外,制程的不成熟也让良率难以有效提高,IBM基于RISC架构的POWER处理器,早在2001年就已经迈入多核心,不过初期仅限于高阶的计算运用,x86平台则是迟至2005年才推出了首款双核心处理器。

图说:Power4的晶片结构。
POWER4的架构为64位元,採用深管线,非循序执行指令(Out-Of-Order Execute)和超纯量(superscalar,即在1个处理器中拥有多重资料流路径的技术,可以藉此加快计算的速度)设计,除此之外,POWER4还能执行POWER指令集。每个POWER4处理器拥有2个载入/储存单元;2个倍精度的乘法浮点计算单元;1个分支预测单元和1个条件程式码暂存器执行单元。2个载入/贮存单元本身也具备了执行简单整数指令的能力,例如加、减和逻辑运算等。
每个POWER4处理器拥有32KB的资料快取(data cache )和64KB的指令快取(instruction cache),资料快取每个时脉週期可以完成2个载入动作和1个贮存动作。L1逻辑控制器支援在资料快取和指令快取中实现硬件指令预取。POWER4是非常先进的架构,远远超越了当时的X86体系。不过POWER4的晶片成本非常高昂,电晶体面积庞大,功耗也相当惊人,也此该处理器在初期仅能被应用在高速资料处理硬件上,直到制程技术有了突破,才逐渐被应用到桌面平台。
x86平台方面要主要是消费性应用,因此价格与成本必须被摆到第一要件考量,双核心晶片面积过于庞大,功耗更是难以利用当时的技术解决,而x86处理器为了能够适应复杂的运算环境,在晶片上设计了许多执行单元,已被不时之需,事实上,这些执行单元在大多数的运算应用中总是被闲置,形成了效能上的浪费,为了解决这样的问题,Intel借镜其他处理器厂商的技术,推出了自有的双执行绪技术,也就是俗称的HyperThreading,藉由该技术,Intel Pentium处理器在单一週期中最多可以执行2道指令,这项技术在当时的x86环境上看起来很新鲜,实际上针对高阶运算的RISC平台早已行之有年,而这项技术也有其缺点,当开启HyperThreading时,因为部分处理单元被切割来作为执行第二个执行绪之用,在面对单一复杂的执行绪运算需求,效能表现反而可能会逊于关闭HyperThreading的状态。
在x86环境当中,微软的作业系统向来无法良好的负担起多核心处理器的资料分配需求,以WindowsXP为例,该作业系统在执行单元与记忆体存取的流程分配上有很大的问题,当双核心处理器的1个核心在进行运算时,另1核心必须等到运算中的核心完成工作之后,才能从L2快取存储器中取得所需资料来进行运算,而如果该运算资料刚好在正在运算的另1核心的L2快取中,则处理器核心还要透过汇流排将对方L2快取资料传输过来,不仅耗费过多执行周期,对汇流排也是相当大的负担。Vista在某种程度上改善了这样的状况,但是存储器控制器仍会影响到处理器核心的资料分配与传输,一般来说,高效能处理器通常都会将存储器控制器内建,如此可以大幅降低存储器存取所造成的延迟,并提供处理器更大的频宽。

图说:具备HyperThreading技术的Intel处理器。
后来Intel逐渐发展成为半导体勐兽,拥有业界最先进的半导体制程技术,双核心设计逐渐取得领先,虽然存储器控制器仍是效能瓶颈,但是藉由不计工本的整合庞大快取存储器,在效能上仍是具有相当的可看性,为了避免抵消庞大快取存储器的加速作用,其对HyperThreading之类的多执行绪技术也采避而不谈的态度,新近的Core 微架构双核心处理器上也没有导入此技术,不过在45nm Penryn处理器家族上,藉由改善快取存储器的效率,将可见到Hyper Threading技术復活。不过将来计算环境预料将大幅向串流应用倾斜,针对此类串流应用,循序(In-Order)执行能力的核心将藉由核心数量以及可运用计算单元取胜,在此类架构导入多执行绪来避免执行管线阻塞,将是未来的设计主流,效率也将会更高。当然,为了避免多执行绪架构对读写效能带来冲击,整合存储器控制器是绝对必须的条件之一。
嵌入式环境中的SoC设计
在嵌入式系统方面,处理器多以SoC的形式进行发展,单一晶片内部可能包含了1到多个同质或非同质处理器核心,情况更不是如前述基本型态多核心处理器那般单纯,由于SoC除了中央处理器核心以外,还要包括了数字信号处理器、丰陈设或周边控制器、音效处理单元、视频处理单元、或是SIMD处理单元,在架构上非常的复杂,在此种型态晶片中采用多核心方案,其实有其困难度。先不论硬件方面的问题,在软件开发与整合方面,就已经是1大难关。
在一般应用上,同质多核心的性能成长幅度无法随着核心数目的增加而线性成长,就目前的例子来看,4核心同质处理器的效能表现,尚无法达到单一核心的3倍幅度,这是因为通用作业系统在安排工作时,通常对排程管理无法达到最佳化,而以一般PC平台最常面对的随机运算特性,系统很难去判断何时是特定核心工作交接或执行的最佳时间点,不过在嵌入式应用方面,其运算环境多为串流应用,或者是可预期的计算过程与资料来源,最佳化过的作业系统可以将不同特性的运算需求分配给不同性质的处理核心(也就是异质多核心),一般通用多核心处理器在此处所扮演的角色其实相当弱。

相关推荐
在线研讨会
焦点